excreationist
Married mouth-breather
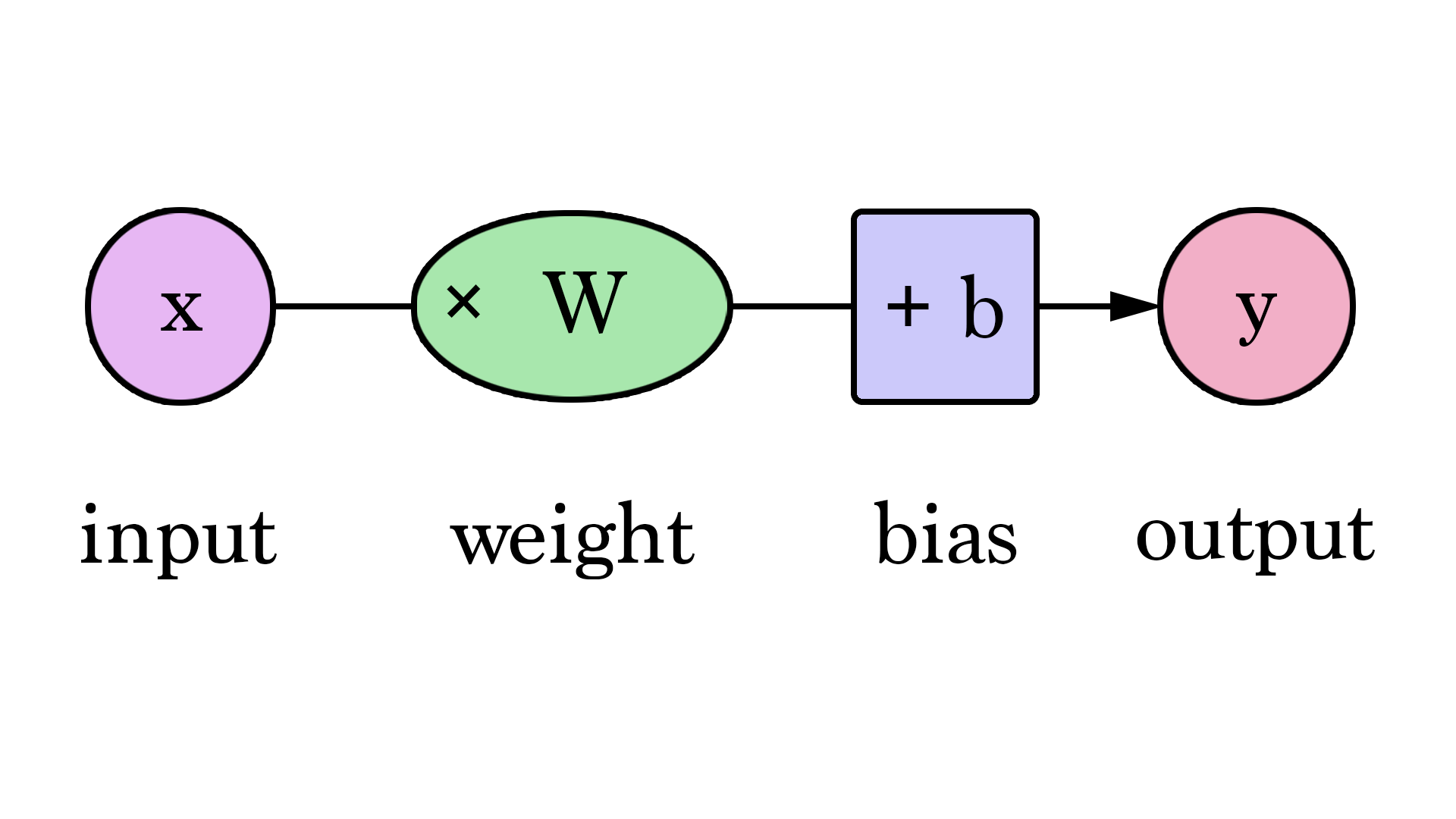
I'm not sure what the best terms are but it is related to neural networks that are loosely based on those in brains - so it is "mental".
In a physical universe the building blocks are sub-atomic particles. Some critics say that a simulation must be on the sub-atomic level.
In modern video games the graphics are usually all made up of pixels and polygons but machine learning would involve what I'm calling "mental elements".
See:

 iidb.org
iidb.org
Here are some examples from a very limited text to image generation AI called DALL-E mini.
I think it has a small amount of what I call "working memory" and has a limit to how much detail it can render. When it doesn't have enough resources it often seems to just use randomness.... (I think it is better to just blur it)
So if it just does a closeup of an eye it is quite detailed.

If you show most of the face the eyes aren't as detailed...

If you have two people their faces are less detailed....

If you have four people their faces are even less detailed...

Another example involves Lego minifig faces:

When many minifigs are in view at once their faces get really messed up:

Maybe it is related to how they say that in dreams you can't really see text.... the system rendering your dreams is also a kind of neural network....


Better text to image systems can generate written words within the output (see thread link)
A surprising thing is how realistic animals like lizards look. My explanation is that the shape of those lizards doesn't vary much so it doesn't contain much independent detail.

So that is how the graphics in a simulation might work...
As far as how the behaviour and dialog of the NPCs (non-player characters) might work see:
iidb.org
In a physical universe the building blocks are sub-atomic particles. Some critics say that a simulation must be on the sub-atomic level.
In modern video games the graphics are usually all made up of pixels and polygons but machine learning would involve what I'm calling "mental elements".
See:
Amazing new AI system - GPT-3 and generating images from text
GPT-3 is based on 175 billion weights such as a lot of Internet content... It can be used in many novel ways... It is pretty good at comprehending natural language - though sometimes has problems.... https://lacker.io/ai/2020/07/06/giving-gpt-3-a-turing-test.html Recently it was used to...
iidb.org
Here are some examples from a very limited text to image generation AI called DALL-E mini.
I think it has a small amount of what I call "working memory" and has a limit to how much detail it can render. When it doesn't have enough resources it often seems to just use randomness.... (I think it is better to just blur it)
So if it just does a closeup of an eye it is quite detailed.
If you show most of the face the eyes aren't as detailed...
If you have two people their faces are less detailed....
If you have four people their faces are even less detailed...
Another example involves Lego minifig faces:
When many minifigs are in view at once their faces get really messed up:
Maybe it is related to how they say that in dreams you can't really see text.... the system rendering your dreams is also a kind of neural network....
Better text to image systems can generate written words within the output (see thread link)
A surprising thing is how realistic animals like lizards look. My explanation is that the shape of those lizards doesn't vary much so it doesn't contain much independent detail.
So that is how the graphics in a simulation might work...
As far as how the behaviour and dialog of the NPCs (non-player characters) might work see:
OpenAI's impressive text-based AI
You can sign up for it - here are some examples.... https://beta.openai.com/playground Complete the story: Once upon a time there was a messageboard called Internet Infidels discussion board and it had an offbeat poster called excreationist. One day, excreationist decided to post a thread...
iidb.org