lpetrich
Contributor
In the West Liao basin, agriculture started with the growing of broomcorn millet around 9000 BP (7000 BCE).
Bayesian phylolinguistics reveals the internal structure of the Transeurasian family | Journal of Language Evolution | Oxford Academic
They used 23 out of 27 present-day Turkic languages and also Old Turkic, 10 out of 17 Mongolic languages and also Written Mongolian and Middle Mongolian, 10 out of 13 Tungusic languages and also Manchu and Jurchen, Korean and also Middle Korean, and Japanese and 5 out of 14 Ryukyuan languages and also Old Japanese.
They also used a 200-word version of the Leipzig–Jakarta list, a list of meanings with seldom-replaced word forms, a list derived using statistics on etymologies. Something like the Swadesh lists, with a lot of overlap.
Leipzig–Jakarta list, a list of meanings with seldom-replaced word forms, a list derived using statistics on etymologies. Something like the Swadesh lists, with a lot of overlap.
"First, among the concepts of the Leipzig-Jakarta list, we find fifty-nine actions, thirty-two property words, twenty-three deictic or grammatical items and eighty-six nominal concepts." and "Empirically, it is observed that languages tend to borrow lexical items more easily than grammatical ones and nouns more easily than verbs (a.o. Wohlgemuth 2009; Matras 2009; Tadmor et al. 2010)." That is, words with standalone meanings tend to be borrowed more easily than words with meanings connected to other words. "In contrast to this tendency, there are more correlations for verbs (65%) and deictic and grammatical items (57%) in the Transeurasian basic vocabulary than for nouns (43%)."
"Second, as far as the mechanisms of loan verb accomodation are concerned, most recipient languages can be categorized into two distinct groups: borrowed verbs either arrive as verbs, needing no formal accommodation, or, they arrive as nonverbs and need formal accommodation. Most Transeurasian languages can be assigned to the second group because they display a clear preference for the nonverbal strategy (Wohlgemuth 2009: 159, 161)." In Japanese, borrowed verbs often have form "to do" <verb> (<verb> suru).
"Third, the comparative sets for basic vocabulary display regular correspondences for each consonant of the verb root and for each but the root-final vowel, conform to the requirements in Supplementary Data (SI 1)." Usually close to other work, like Palaeolexicon - Table of (Macro-) Altaic Phonology
"Fourth, gaps in the attestation of members of an etymology, whereby a cognate is absent in one or more intermediate contact branches are indicative of borrowing."
"Fifth, most examples of borrowing have a binary setting in common: they typically go from a model language into a recipient language. Especially for verbs and grammatical markers, examples of the same item progressing into a third or fourth language are relatively rare." - but it is grammatical items and verbs that are best-preserved of the cognate list used.
"Finally, the distribution of a certain basic item to a single language or to only few languages of a certain subgroup could serve as an indication of borrowing. However, such cases do not occur among our basic vocabulary etymologies."
Bayesian phylolinguistics reveals the internal structure of the Transeurasian family | Journal of Language Evolution | Oxford Academic
They used 23 out of 27 present-day Turkic languages and also Old Turkic, 10 out of 17 Mongolic languages and also Written Mongolian and Middle Mongolian, 10 out of 13 Tungusic languages and also Manchu and Jurchen, Korean and also Middle Korean, and Japanese and 5 out of 14 Ryukyuan languages and also Old Japanese.
They also used a 200-word version of the
They then go into detail.It is highly unlikely that all similarities between the basic items in our dataset are the result of contact instead of genealogical relationship. Traditionally, the strength of basic vocabulary lies in the fact that words with basic meanings tend to resist borrowing more successfully than random lexical items. The very fact that we find 150 Transeurasian etymologies covering 107 distinct basic vocabulary concepts thus is a strong argument against borrowing by itself. In addition, we can advance other arguments against borrowing, such as (1) the misfit with the expected borrowing hierarchy; (2) the misfit with the expected typology of verbal borrowing; (3) the regularity and complexity of sound correspondence; (4) the occurrence of broken contact chains; (5) the multiple setting; and (6) the well-spread distribution of the cognates; see also Robbeets (in press, 2019).
"First, among the concepts of the Leipzig-Jakarta list, we find fifty-nine actions, thirty-two property words, twenty-three deictic or grammatical items and eighty-six nominal concepts." and "Empirically, it is observed that languages tend to borrow lexical items more easily than grammatical ones and nouns more easily than verbs (a.o. Wohlgemuth 2009; Matras 2009; Tadmor et al. 2010)." That is, words with standalone meanings tend to be borrowed more easily than words with meanings connected to other words. "In contrast to this tendency, there are more correlations for verbs (65%) and deictic and grammatical items (57%) in the Transeurasian basic vocabulary than for nouns (43%)."
"Second, as far as the mechanisms of loan verb accomodation are concerned, most recipient languages can be categorized into two distinct groups: borrowed verbs either arrive as verbs, needing no formal accommodation, or, they arrive as nonverbs and need formal accommodation. Most Transeurasian languages can be assigned to the second group because they display a clear preference for the nonverbal strategy (Wohlgemuth 2009: 159, 161)." In Japanese, borrowed verbs often have form "to do" <verb> (<verb> suru).
"Third, the comparative sets for basic vocabulary display regular correspondences for each consonant of the verb root and for each but the root-final vowel, conform to the requirements in Supplementary Data (SI 1)." Usually close to other work, like Palaeolexicon - Table of (Macro-) Altaic Phonology
"Fourth, gaps in the attestation of members of an etymology, whereby a cognate is absent in one or more intermediate contact branches are indicative of borrowing."
"Fifth, most examples of borrowing have a binary setting in common: they typically go from a model language into a recipient language. Especially for verbs and grammatical markers, examples of the same item progressing into a third or fourth language are relatively rare." - but it is grammatical items and verbs that are best-preserved of the cognate list used.
"Finally, the distribution of a certain basic item to a single language or to only few languages of a certain subgroup could serve as an indication of borrowing. However, such cases do not occur among our basic vocabulary etymologies."

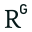
") Briefly, Danish residents of the Danelaw retained their language. When William the Bastard and the Normans arrived and the natives resisted, the English-vs-Danish political situation flipped completely. Since one's enemy's enemy is one's ally there was suddenly incentive to merge (or form a koine of) two languages which were already close enough to facilitate bilingualism; it was even politically expedient to try for a 50-50 combination! As London — just to the South of the Danelaw — became the new center of England (and underwent a big influx of immigrants from the Danelaw region), Anglicized Norse (or Norsified English in the traditional view) became the new standard of English.
Briefly, Danish residents of the Danelaw retained their language. When William the Bastard and the Normans arrived and the natives resisted, the English-vs-Danish political situation flipped completely. Since one's enemy's enemy is one's ally there was suddenly incentive to merge (or form a koine of) two languages which were already close enough to facilitate bilingualism; it was even politically expedient to try for a 50-50 combination! As London — just to the South of the Danelaw — became the new center of England (and underwent a big influx of immigrants from the Danelaw region), Anglicized Norse (or Norsified English in the traditional view) became the new standard of English.