-
Features
-
Friends of IIDBFriends Recovering from Religion United Coalition of Reason Infidel Guy
Forums Council of Ex-Muslims Rational Skepticism
Social Networks Internet Infidels Facebook Page IIDB Facebook Group
The Archives IIDB Archive Secular Café Archive
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The Programming Thread
- Thread starter rousseau
- Start date
steve_bank
Diabetic retinopathy and poor eyesight. Typos ...
I've spent some effort working with random numbers. Not the PRNGs themselves (though I'm sure that's fascinating) but how to "massage" the random bits once you get them.
For example, assume (perhaps just for fun) that random-number generation is very expensive. To make a 50-50 random coin toss you only need to expend one random bit. But what about a 53-47 biased coin? Most code will "brutishly" use up a word's worth of random bits, but you can actually make do (and my random library does) with less than one random bit on average!
Another good exercise is to select a random point uniformly in an N-ball. (If this seems trivial, consider when N is large.)
Before you get too carried away with an alternative to rot13, note that these characters come from the UTF-16 Supplemental Planes. Let's make sure the TFT rendering works:
𐎀 𐎁 𐎂 𐎃 𐎄 𐎅 𐎆 𐎇
𐎈 𐎉 𐎊 𐎋 𐎌 𐎍 𐎎 𐎏
𐎐 𐎑 𐎒 𐎓 𐎔 𐎕 𐎖 𐎗
𐎘 𐎙 𐎚 𐎛 𐎜 𐎝 𐎟
Looks OK on Preview.
Way back wehn working s a manufacturng enineer I used the clsing numbers from the stck exchnges to index into a book of random numbers for a staring point.
Gnerating a large array of random numbers with pseudo random techiques means a larger size to avoid a sequnce repeting itself.
Other techniques use electrical noise from a diode and cosmic radiation.
A brute force method. Put N balls in a container one for each point, shake it, pick one, put it back in, shake, and repeat.
Tailor the generator to create a random integer from 1:N.
Dude, 8088 did "random" numbers in a beowulf array headless and all it gave me is _/\, monochrome orange, and system V manuals.
Needless I won the lottery, at least once and paid the energy grid for future generations. L0L, yeah seen more green than paper white, and dam that oracle 14 floppy FIDO meh gopher served better.
L0pht the paper, 220 to 12 volt then I find that big data link and everybody got scared and pulled... let's just say remorse.
Needless I won the lottery, at least once and paid the energy grid for future generations. L0L, yeah seen more green than paper white, and dam that oracle 14 floppy FIDO meh gopher served better.
L0pht the paper, 220 to 12 volt then I find that big data link and everybody got scared and pulled... let's just say remorse.
steve_bank
Diabetic retinopathy and poor eyesight. Typos ...
Oky dokey.
steve_bank
Diabetic retinopathy and poor eyesight. Typos ...
RMS Value Of A Signal
RMS Root Mean Squared. In statistics it is the standard deviation, same calculation.
RSS Root Sum Squared. RMS values add by RSS.
RMS represents the energy in a signal. Equal RMS means equal thermal equivalent.
Average values can be zero and the sane average values does not equate to equal thermal equivalent. Hence RMS. Find the average , subtracr each data point and square.
The RMS value is the AC portionof the signal. The total RMS vale is the RSS 0f the AC RMS and dc average,
void rms(double* out, double* y, int N) {
double sum = 0, _rss = 0, _rms = 0, dc_avg = 0;
for (int i = 0; i < N; i++) sum += y;
dc_avg = sum / double(N);
sum = 0;
for (int i = 0; i < N; i++) sum += pow(dc_avg - y, 2.);
_rms = sqrt(abs(sum) / double(N));
_rss = sqrt(pow(_rms, 2.) + pow(dc_avg, 2.));
out[0] = _rms;
out[1] = _rss;
out[2] = dc_avg;
}//rms()
Code to demonstrate. I compile functions to object files and lnk to other code.
extern void rms(double*, double*, int);
const int N = 1000;
int main() {
double *y = new double[N];
double out[3],dc, A, freq, t, dt = 1. / double(N);
t = 0;
freq = 10;
A = 1;
dc = 10;
for (int i = 0; i < N; i++) { y = A * sin(2 * _PI * freq * t) + dc; t += dt; }
rms(out, y, N);
printf("DC AVG %f RMS %f RSS %f \n", out[2], out[0],out[1]);
delete [] y;
return(0);
}//main()
RMS Root Mean Squared. In statistics it is the standard deviation, same calculation.
RSS Root Sum Squared. RMS values add by RSS.
RMS represents the energy in a signal. Equal RMS means equal thermal equivalent.
Average values can be zero and the sane average values does not equate to equal thermal equivalent. Hence RMS. Find the average , subtracr each data point and square.
The RMS value is the AC portionof the signal. The total RMS vale is the RSS 0f the AC RMS and dc average,
void rms(double* out, double* y, int N) {
double sum = 0, _rss = 0, _rms = 0, dc_avg = 0;
for (int i = 0; i < N; i++) sum += y;
dc_avg = sum / double(N);
sum = 0;
for (int i = 0; i < N; i++) sum += pow(dc_avg - y, 2.);
_rms = sqrt(abs(sum) / double(N));
_rss = sqrt(pow(_rms, 2.) + pow(dc_avg, 2.));
out[0] = _rms;
out[1] = _rss;
out[2] = dc_avg;
}//rms()
Code to demonstrate. I compile functions to object files and lnk to other code.
extern void rms(double*, double*, int);
const int N = 1000;
int main() {
double *y = new double[N];
double out[3],dc, A, freq, t, dt = 1. / double(N);
t = 0;
freq = 10;
A = 1;
dc = 10;
for (int i = 0; i < N; i++) { y = A * sin(2 * _PI * freq * t) + dc; t += dt; }
rms(out, y, N);
printf("DC AVG %f RMS %f RSS %f \n", out[2], out[0],out[1]);
delete [] y;
return(0);
}//main()
Swammerdami
Squadron Leader
Ordinary Linear Regression
In my posts, I try to achieve a balance between rigor and a simple intuitive presentation.
For this post I sacrifice rigor, and just try to outline why linear regression is elegant!
There are many applications where RMS simply provides the correct answer to a problem. No substitutions permitted. But what about as an arbitrary measure of disparity?
When the number of points is fixed, and monotonic transfers are irrelevant, TSE (total squared error) is equivalent to RMSE and may be slightly more convenient to work with.
TSE = Σ (ypredict - yactual)2
But what about arbitrary measures of disparity? Instead of TSE, some analysrs prefer Total Absolute Error
TAE = Σ |ypredict - yactual|
or why not allow more flexibility and allow an analyst to pick whatever exponent β seems to work best in his application?
TXE = Σ |ypredict - yactual|β
But there is a lovely reason why the default exponent for measuring the efficacy of a linear prediction filter is β=2, the Total Squared Error.
The following outline of Ordinary Linear Regression is incomplete, but may still depict the underlying mathematical elegance!
We are given a "training set" of tuples (xa,1, xa,2, xa,3, ... xa,N) and the associated targets ya. The goal is to find an "optimal filter" whose dot-product with an input tuple best approximates the target value inferred from the training set.
The following is VERY sloppy. In particular, some of the A's should be AT. (Nonsense! The way A is defined, A = AT.) Corrections welcome.
Let A be the NxN matrix containing the sums Σ (xa,i·xa,j) of each (i,j) pair of coordinates across the training set.
Let F be the parameters we seek, i.e. the "filter" whose dot-product with a datum best predicts the target value.
Let T be the Nx1 vector containing the sums Σ (xa,i·ya) across the training set.
So (A·F - T) gives a form of the signed difference sum between predicted and actual targets. Square that to get the Total Squared Error!
TSE = (A·F - T)2 = (A·F)2 - 2A·F·T + T2
Let's find the F which minimizes Total Squared Error. Pretending that A, F, T are ordinary real variables instead of vectors or matrixes we expect the minimum when
d((A·F)2 - 2A·F·T + T2) / dF = 0
If we differentiate in the naive way, this becomes 2A·A·F - 2A·T = 0 or simply A·F = T.
To solve A·F = T for F, we just invert the matrix A and multiply by A-1 to get A-1·A·F = A-1·T, or simply
F = A-1·T
Presto! We've found the optimal prediction filter F !! But this only worked because differentiating a square is so simple. This is a major reason why the TSE (or RMSE) is such a popular measure of disparity! It leads to the trivial solution called Ordinary Linear Regression.
Like the drunkard looking for his keys under the lamppost because the "light is better here" even though he lost the keys on the opposite side of the street, analysts will often use TSE (equiv. RMSE) as their disparity measure even knowing some other β might be better. Zip through the training data, invert a matrix and ... after one multiply, You've found the optimal linear predictor!
In my posts, I try to achieve a balance between rigor and a simple intuitive presentation.
For this post I sacrifice rigor, and just try to outline why linear regression is elegant!
RMS Value Of A Signal
RMS Root Mean Squared. In statistics it is the standard deviation, same calculation.
RSS Root Sum Squared. RMS values add by RSS.
RMS represents the energy in a signal. Equal RMS means equal thermal equivalent.
There are many applications where RMS simply provides the correct answer to a problem. No substitutions permitted. But what about as an arbitrary measure of disparity?
When the number of points is fixed, and monotonic transfers are irrelevant, TSE (total squared error) is equivalent to RMSE and may be slightly more convenient to work with.
TSE = Σ (ypredict - yactual)2
But what about arbitrary measures of disparity? Instead of TSE, some analysrs prefer Total Absolute Error
TAE = Σ |ypredict - yactual|
or why not allow more flexibility and allow an analyst to pick whatever exponent β seems to work best in his application?
TXE = Σ |ypredict - yactual|β
But there is a lovely reason why the default exponent for measuring the efficacy of a linear prediction filter is β=2, the Total Squared Error.
The following outline of Ordinary Linear Regression is incomplete, but may still depict the underlying mathematical elegance!
We are given a "training set" of tuples (xa,1, xa,2, xa,3, ... xa,N) and the associated targets ya. The goal is to find an "optimal filter" whose dot-product with an input tuple best approximates the target value inferred from the training set.
The following is VERY sloppy. In particular, some of the A's should be AT. (Nonsense! The way A is defined, A = AT.) Corrections welcome.
Let A be the NxN matrix containing the sums Σ (xa,i·xa,j) of each (i,j) pair of coordinates across the training set.
Let F be the parameters we seek, i.e. the "filter" whose dot-product with a datum best predicts the target value.
Let T be the Nx1 vector containing the sums Σ (xa,i·ya) across the training set.
So (A·F - T) gives a form of the signed difference sum between predicted and actual targets. Square that to get the Total Squared Error!
TSE = (A·F - T)2 = (A·F)2 - 2A·F·T + T2
Let's find the F which minimizes Total Squared Error. Pretending that A, F, T are ordinary real variables instead of vectors or matrixes we expect the minimum when
d((A·F)2 - 2A·F·T + T2) / dF = 0
If we differentiate in the naive way, this becomes 2A·A·F - 2A·T = 0 or simply A·F = T.
To solve A·F = T for F, we just invert the matrix A and multiply by A-1 to get A-1·A·F = A-1·T, or simply
F = A-1·T
Presto! We've found the optimal prediction filter F !! But this only worked because differentiating a square is so simple. This is a major reason why the TSE (or RMSE) is such a popular measure of disparity! It leads to the trivial solution called Ordinary Linear Regression.
Like the drunkard looking for his keys under the lamppost because the "light is better here" even though he lost the keys on the opposite side of the street, analysts will often use TSE (equiv. RMSE) as their disparity measure even knowing some other β might be better. Zip through the training data, invert a matrix and ... after one multiply, You've found the optimal linear predictor!
Last edited:
steve_bank
Diabetic retinopathy and poor eyesight. Typos ...
Jumping over from the beyond C++ thread.
Static variables and getting data out from a function.
In C I used pointers to variables or arrays to get data out. In C++ I used objects. You can spawn multiple objects without having to worrying about variable name conflicts.
A simple function to calculate the running average as new values are added. The C functions use static variables to keep the data between calls.
double running_avg1(double new_val,int reset){
//single value return
static int n;
static double sum,n;
if(reset){ sum = 0; n = 0;}
else{ sum += new_val; n++;}
if(n > 0)return(sum/n);else return(0);
}
void running_avg2(double new_val,int reset, double r[]){
//return to array
static double sum, n;
if(reset){ sum = 0; n = 0;}
else{ sum += new_val; n++;}
if(n > 0){r[0] = n; r[1] = sum/n;}
else{r[0] = 0; r[1] = 0;}
}
void running_avg(double new_val,int reset, double *c,double *a){
//return via pointers
static double sum, n;
if(reset){ sum = 0; n = 0;}
else{ sum += new_val; n++;}
if(n > 0){*c = n; *a = sum/n;}
else{ *c = 0; *a = 0;}
}
class running_average{
public:
double count,average;
void reset(void);
void update(double new_val);
private:
double sum;
};
void running_average::reset(void){count = 0;average = 0;sum = 0;}
void running_average::update(double new_val){
count++;
sum += new_val;
average = sum/count;
}
int main()
{
running_average ra1;
double avg, count;
running_avg(0,1,&count,&avg);
printf("n %f avg %f\n",count,avg);
running_avg(10,0,&count,&avg);
printf("n %f avg %f\n",count,avg);
running_avg(40,0,&count,&avg);
printf("n %f avg %f\n",count,avg);
ra1.reset();
printf("count %f aver %f\n", ra1.count,ra1.average);
ra1.update(10);
printf("count %f aver %f\n", ra1.count,ra1.average);
ra1.update(40);
printf("count %f aver %f\n", ra1.count,ra1.average);
}
Static variables and getting data out from a function.
In C I used pointers to variables or arrays to get data out. In C++ I used objects. You can spawn multiple objects without having to worrying about variable name conflicts.
A simple function to calculate the running average as new values are added. The C functions use static variables to keep the data between calls.
double running_avg1(double new_val,int reset){
//single value return
static int n;
static double sum,n;
if(reset){ sum = 0; n = 0;}
else{ sum += new_val; n++;}
if(n > 0)return(sum/n);else return(0);
}
void running_avg2(double new_val,int reset, double r[]){
//return to array
static double sum, n;
if(reset){ sum = 0; n = 0;}
else{ sum += new_val; n++;}
if(n > 0){r[0] = n; r[1] = sum/n;}
else{r[0] = 0; r[1] = 0;}
}
void running_avg(double new_val,int reset, double *c,double *a){
//return via pointers
static double sum, n;
if(reset){ sum = 0; n = 0;}
else{ sum += new_val; n++;}
if(n > 0){*c = n; *a = sum/n;}
else{ *c = 0; *a = 0;}
}
class running_average{
public:
double count,average;
void reset(void);
void update(double new_val);
private:
double sum;
};
void running_average::reset(void){count = 0;average = 0;sum = 0;}
void running_average::update(double new_val){
count++;
sum += new_val;
average = sum/count;
}
int main()
{
running_average ra1;
double avg, count;
running_avg(0,1,&count,&avg);
printf("n %f avg %f\n",count,avg);
running_avg(10,0,&count,&avg);
printf("n %f avg %f\n",count,avg);
running_avg(40,0,&count,&avg);
printf("n %f avg %f\n",count,avg);
ra1.reset();
printf("count %f aver %f\n", ra1.count,ra1.average);
ra1.update(10);
printf("count %f aver %f\n", ra1.count,ra1.average);
ra1.update(40);
printf("count %f aver %f\n", ra1.count,ra1.average);
}
Jarhyn
Wizard
- Joined
- Mar 29, 2010
- Messages
- 17,426
- Gender
- Androgyne; they/them
- Basic Beliefs
- Natural Philosophy, Game Theoretic Ethicist
You put me on the path to something that helped me at work, with this!!Ordinary Linear Regression
In my posts, I try to achieve a balance between rigor and a simple intuitive presentation.
For this post I sacrifice rigor, and just try to outline why linear regression is elegant!
RMS Value Of A Signal
RMS Root Mean Squared. In statistics it is the standard deviation, same calculation.
RSS Root Sum Squared. RMS values add by RSS.
RMS represents the energy in a signal. Equal RMS means equal thermal equivalent.
There are many applications where RMS simply provides the correct answer to a problem. No substitutions permitted. But what about as an arbitrary measure of disparity?
When the number of points is fixed, and monotonic transfers are irrelevant, TSE (total squared error) is equivalent to RMSE and may be slightly more convenient to work with.
TSE = Σ (ypredict - yactual)2
But what about arbitrary measures of disparity? Instead of TSE, some analysrs prefer Total Absolute Error
TAE = Σ |ypredict - yactual|
or why not allow more flexibility and allow an analyst to pick whatever exponent β seems to work best in his application?
TXE = Σ |ypredict - yactual|β
But there is a lovely reason why the default exponent for measuring the efficacy of a linear prediction filter is β=2, the Total Squared Error.
The following outline of Ordinary Linear Regression is incomplete, but may still depict the underlying mathematical elegance!
We are given a "training set" of tuples (xa,1, xa,2, xa,3, ... xa,N) and the associated targets ya. The goal is to find an "optimal filter" whose dot-product with an input tuple best approximates the target value inferred from the training set.
The following is VERY sloppy. In particular, some of the A's should be AT. (Nonsense! The way A is defined, A = AT.) Corrections welcome.
Let A be the NxN matrix containing the sums Σ (xa,i·xa,j) of each (i,j) pair of coordinates across the training set.
Let F be the parameters we seek, i.e. the "filter" whose dot-product with a datum best predicts the target value.
Let T be the Nx1 vector containing the sums Σ (xa,i·ya) across the training set.
So (A·F - T) gives a form of the signed difference sum between predicted and actual targets. Square that to get the Total Squared Error!
TSE = (A·F - T)2 = (A·F)2 - 2A·F·T + T2
Let's find the F which minimizes Total Squared Error. Pretending that A, F, T are ordinary real variables instead of vectors or matrixes we expect the minimum when
d((A·F)2 - 2A·F·T + T2) / dF = 0
If we differentiate in the naive way, this becomes 2A·A·F - 2A·T = 0 or simply A·F = T.
To solve A·F = T for F, we just invert the matrix A and multiply by A-1 to get A-1·A·F = A-1·T, or simply
F = A-1·T
Presto! We've found the optimal prediction filter F !! But this only worked because differentiating a square is so simple. This is a major reason why the TSE (or RMSE) is such a popular measure of disparity! It leads to the trivial solution called Ordinary Linear Regression.
Like the drunkard looking for his keys under the lamppost because the "light is better here" even though he lost the keys on the opposite side of the street, analysts will often use TSE (equiv. RMSE) as their disparity measure even knowing some other β might be better. Zip through the training data, invert a matrix and ... after one multiply, You've found the optimal linear predictor!
steve_bank
Diabetic retinopathy and poor eyesight. Typos ...
A few odds and ends, displaying numbers as hex and binary strings.
Code:
const int string_null_error = 1;
const int no_error = 0;
int hex_string(char *s, unsigned int x){
if(s[4] != NULL)return(string_null_error);
char hex[16]=
{'0','1','2','3','4','5','6',
'7','8','9','a','b','c','d','e','f'};
unsigned int y = 0, mask = 0xf000;
int i = 0;
for (i = 0;i < 4;i++){
y = x & mask;
s[i] = hex[y];
mask >>= 4;
}//for
return(no_error);
}//hex_straing()
int bin_string(char *s, unsigned int x){
if(s[16] != NULL)return(string_null_error);
unsigned int mask = 0x8000;
int i = 0;
for (i = 0;i< 16;i++){
if(x & mask) s[i] = '1';
else s[i] = '0';
mask >>= 1;
}//for
return(no_error);
}//bin_string()
int main(){
unsigned int y = 0x000a;
int error = 0;
char hex_str[5], bin_str[17];
hex_str[4] = NULL;
bin_str[16] = NULL;
error = hex_string(hex_str, y);
printf("hex string 0X%s\n",hex_str);
if(error)printf(" DANGER Will Robinson!!! Unterminated String\n");
error = bin_string(bin_str, y);
printf("bin string %s\n",bin_str);
if(error)printf("Scotty I need that string terminated NOW!!!\n");
return(0);
}main()steve_bank
Diabetic retinopathy and poor eyesight. Typos ...
Not that it matters, looks like a copied out while I was tinkering.
The hex string function is
The hex string function is
Code:
int hex_string(char *s, unsigned int x){
if(s[4] != NULL)return(string_null_error);
char hex[16] ={'0','1','2','3','4','5','6','7','8','9',
'a','b','c','d','e','f'};
unsigned int y = 0, mask = 0x000f;
int i = 0;
for (i = 0;i < 4;i++){
y = x & mask;
s[3-i] = hex[y];
x >>= 4;
}//for
return(no_error);
}//hex_straing()steve_bank
Diabetic retinopathy and poor eyesight. Typos ...
From the math thread on infinite sums.
When iterating a numerical sequence one way to shorten run time is to stop when a steady state condition is reached. That would be when the percent change of the variable goes below a value.
Evaluating the sum of 1/(x^p) a x goes to infinity.
When iterating a numerical sequence one way to shorten run time is to stop when a steady state condition is reached. That would be when the percent change of the variable goes below a value.
Evaluating the sum of 1/(x^p) a x goes to infinity.
Code:
const int FOREVER = 1;
int main()
{
double steady_state = 1e-10, p = 1,x = 1, sum_now = 0,sum_last = 0;
double perc_change = 100, limit = pow(2,32);
while(FOREVER){
sum_now += 1/pow(x,p);
x++;
//avoid /0 on start up
if(x > 1)perc_change =100*(sum_now - sum_last)/sum_last;
if(perc_change < steady_state){printf("steady state\n");break;}
if( x > limit){printf("limit\n");break;}
sum_last = sum_now;
}
printf("x %f P %f Sum %f\n", x, p, sum_now);
printf("pc %1.10f ss %1.10f\n",perc_change,steady_state);
return 0;
}lpetrich
Contributor
God-Tier Developer Roadmap - YouTube
Classification of programming languages by level.
# Making programming easy - Scratch (MIT, 2003, Basic (Dartmouth, 1964)
Scratch - one programs by moving blocks representing variables and operators and control structures.
Basic - Beginners' All-Symbolic Instruction Code - an early and simplified language
# Popular dynamic high-level languages - Python (Netherlands, 1991), JavaScript (USA, 1995)
Python - implified syntax: indentation instead of braces like in C
JavaScript - ugly syntax, but supported by web browsers
# Specialized dynamic high-level languages - Bash, PowerShell, HTML, CSS, SQL (USA, 1979), PHP (Canada, 1994), Lua (Brazil, 1993), Ruby (Japan, 1995), R (New Zealand, 1995), Julia (MIT, 2009)
Bash - Bourne-Again Shell - a command-line-shell programming language
PowerShell - like Bash, but for Windows
HTML - Hypertext Markup Language - webpage structure
CSS - Cascading Style Sheets - webpage styling
SQL - Structured Query Language - for accessing databases
PHP - PHP: Hypertext Processor - server-side for dynamic webpages
Lua - Portuguese: "Moon" - often embedded in game engines
Ruby - much like Python
R - for doing statistics and data science
Julia - for parallel-processing number-crunching
# Static high-level languages - Java (USA, 1995), C# (USA, 2002), TypeScript (USA, 2012), Kotlin (Czechia, 2016), Swift (USA, 2014), Dart (USA, 2013), Go (USA, 2009)
Java - awkward syntax, but write once, run anywhere
C# - C Sharp (step up from C) - Microsoft - often embedded in game engines
TypeScript - statically typed front end for JavaScript
Kotlin - front end for Java
Swift - Apple - front end for Objective-C
Dart - Google
Go - Google - C alternative
# Functional languages - Haskell (global, 1990), F Sharp (USA, 2005), Scala (2004, Switzerland), Clojure (USA, 2007), OCaml (France, 2005), Elixir (Brazil, 2012), Elm (Harvard, 2012),
Variables are immutable and functions have no side effects. One can do everything with functions, though some functional languages also support object orientation.
Scala and Clojure, like Kotlin, run on the Java Virtual Machine. Elm compiles to JavaScript.
# Systems languages - C (USA, 1969), C++ (USA, 1986), Rust
C - very low-level by high-level-langauge standards
C++ - C plus plus (step up from C) - object-oriented programming, generics
Rust - borrow-checker system for memory safety
Classification of programming languages by level.
# Making programming easy - Scratch (MIT, 2003, Basic (Dartmouth, 1964)
Scratch - one programs by moving blocks representing variables and operators and control structures.
Basic - Beginners' All-Symbolic Instruction Code - an early and simplified language
# Popular dynamic high-level languages - Python (Netherlands, 1991), JavaScript (USA, 1995)
Python - implified syntax: indentation instead of braces like in C
JavaScript - ugly syntax, but supported by web browsers
# Specialized dynamic high-level languages - Bash, PowerShell, HTML, CSS, SQL (USA, 1979), PHP (Canada, 1994), Lua (Brazil, 1993), Ruby (Japan, 1995), R (New Zealand, 1995), Julia (MIT, 2009)
Bash - Bourne-Again Shell - a command-line-shell programming language
PowerShell - like Bash, but for Windows
HTML - Hypertext Markup Language - webpage structure
CSS - Cascading Style Sheets - webpage styling
SQL - Structured Query Language - for accessing databases
PHP - PHP: Hypertext Processor - server-side for dynamic webpages
Lua - Portuguese: "Moon" - often embedded in game engines
Ruby - much like Python
R - for doing statistics and data science
Julia - for parallel-processing number-crunching
# Static high-level languages - Java (USA, 1995), C# (USA, 2002), TypeScript (USA, 2012), Kotlin (Czechia, 2016), Swift (USA, 2014), Dart (USA, 2013), Go (USA, 2009)
Java - awkward syntax, but write once, run anywhere
C# - C Sharp (step up from C) - Microsoft - often embedded in game engines
TypeScript - statically typed front end for JavaScript
Kotlin - front end for Java
Swift - Apple - front end for Objective-C
Dart - Google
Go - Google - C alternative
# Functional languages - Haskell (global, 1990), F Sharp (USA, 2005), Scala (2004, Switzerland), Clojure (USA, 2007), OCaml (France, 2005), Elixir (Brazil, 2012), Elm (Harvard, 2012),
Variables are immutable and functions have no side effects. One can do everything with functions, though some functional languages also support object orientation.
Scala and Clojure, like Kotlin, run on the Java Virtual Machine. Elm compiles to JavaScript.
# Systems languages - C (USA, 1969), C++ (USA, 1986), Rust
C - very low-level by high-level-langauge standards
C++ - C plus plus (step up from C) - object-oriented programming, generics
Rust - borrow-checker system for memory safety
lpetrich
Contributor
More:
# Modern languages that are not very well-known - V (Netherlands, 2019), Zig (USA, 2016), Nim (Germany, 2008), Carbon (USA, 2025?), Solidity (global, 2018), Hack (USA, 2014), Crystal, Hax, Pharo, ...
V - C alternative like Go
Zig - C alternative
Nim - has controllable garbage-collection memory management
Carbon - C++ alternative
Solidity - for Ethereum cryptocurrency smart contracts
Hack - alternative to PHP for running Facebook
# Historically important languages - Fortran (USA, 1957), Lisp (MIT, 1958), Algol (USA, 1958), Cobol (USA, 1959), APL (Harvard, 1962), Pascal (Switzerland, 1970), Simula (Norway, 1962), Smalltalk (USA, 1980), Erlang (Sweden, 1986), Ada (USA, 1977), Prolog (1972, France), ML (Scotland, 1973)
Fortran - Formula Translator - first high-level language - C-like
Lisp - List Processing / Lots of Irritating Superfluous Parentheses
Algol - Algorithmic Language - big influence with its structured programming - C-like
Cobol - Common Business-Oriented Language - attempted a natural-language-like appearance
APL - A Programming Language - array-manipulation features, uses single symbols for built-in functions
Pascal - C-like
Simula - first object-oriented language - C++ uses its object syntax
Smalltalk - object-oriented language - Objective-C uses its object syntax
Erlang - functional
Ada - after Charles Babbage's friend Ada Lovelace - C-like
Prolog - logic programming (supply constraints and the software will find what satisfies them)
ML - Meta Language - functional
# Esoteric languages - Intercal (USA, 1972), Brainfuck (Switzerland, 1993), Malbolge (1998), Chef (2002), Shakespeare (2001), Piet, Lolcode, Emojicode, C--, Holy C (USA, 2005)
Intercal - parody language
Chef - like cooking recipes
Shakespeare - like the original's poems
Piet - after painter Piet Mondrian - uses color patterns
Lolcode - uses lolcat vocabulary
Emojicode - uses emojis
# Modern languages that are not very well-known - V (Netherlands, 2019), Zig (USA, 2016), Nim (Germany, 2008), Carbon (USA, 2025?), Solidity (global, 2018), Hack (USA, 2014), Crystal, Hax, Pharo, ...
V - C alternative like Go
Zig - C alternative
Nim - has controllable garbage-collection memory management
Carbon - C++ alternative
Solidity - for Ethereum cryptocurrency smart contracts
Hack - alternative to PHP for running Facebook
# Historically important languages - Fortran (USA, 1957), Lisp (MIT, 1958), Algol (USA, 1958), Cobol (USA, 1959), APL (Harvard, 1962), Pascal (Switzerland, 1970), Simula (Norway, 1962), Smalltalk (USA, 1980), Erlang (Sweden, 1986), Ada (USA, 1977), Prolog (1972, France), ML (Scotland, 1973)
Fortran - Formula Translator - first high-level language - C-like
Lisp - List Processing / Lots of Irritating Superfluous Parentheses
Algol - Algorithmic Language - big influence with its structured programming - C-like
Cobol - Common Business-Oriented Language - attempted a natural-language-like appearance
APL - A Programming Language - array-manipulation features, uses single symbols for built-in functions
Pascal - C-like
Simula - first object-oriented language - C++ uses its object syntax
Smalltalk - object-oriented language - Objective-C uses its object syntax
Erlang - functional
Ada - after Charles Babbage's friend Ada Lovelace - C-like
Prolog - logic programming (supply constraints and the software will find what satisfies them)
ML - Meta Language - functional
# Esoteric languages - Intercal (USA, 1972), Brainfuck (Switzerland, 1993), Malbolge (1998), Chef (2002), Shakespeare (2001), Piet, Lolcode, Emojicode, C--, Holy C (USA, 2005)
Intercal - parody language
Chef - like cooking recipes
Shakespeare - like the original's poems
Piet - after painter Piet Mondrian - uses color patterns
Lolcode - uses lolcat vocabulary
Emojicode - uses emojis
lpetrich
Contributor
Still more:
# Lowest software levels - assembly language (1947), machine code (binary numbers: 1679)
Assembly language - symbolic version of machine language, with operation codes (opcodes) in symbolic form, and with labels for data locations and flow-of-control locations
Machine code - what a CPU directly uses
# Hardware - transistors (1947), logic gates (1935) - I'd add vacuum tubes, electromechanical relays, and clockwork
# How elementary particles work - quantum electrodynamics (1927) - I'd add quantum mechanics more generally
# Yourself - what is knowledge?
# Lowest software levels - assembly language (1947), machine code (binary numbers: 1679)
Assembly language - symbolic version of machine language, with operation codes (opcodes) in symbolic form, and with labels for data locations and flow-of-control locations
Machine code - what a CPU directly uses
# Hardware - transistors (1947), logic gates (1935) - I'd add vacuum tubes, electromechanical relays, and clockwork
# How elementary particles work - quantum electrodynamics (1927) - I'd add quantum mechanics more generally
# Yourself - what is knowledge?
steve_bank
Diabetic retinopathy and poor eyesight. Typos ...
Solvers And Optimizers.
Complex problems tend to be non linear. This means you can't just plug in numbers and apply linear algebra.
The brute force method is to create variable arrays and try all combinations. The solver iterates until outputs are within a specified range. You can start at low resolution and wide limits and successively narrow. A commercial package will automate the process.
The goal is not necessarily to find exact values. When optimizing you are looking for a workable solution. Process controls are an example. A complex system can have hundreds of equations.
If you run it you can experiment with different equations. You can solve simultaneous differential equations. It can be a lot faster than trying to find a closed soltion toa problem.
a = 2*x + y[j];
b = x + pow(2.718,y[j]);
Excel has a solver-optimizer.
Complex problems tend to be non linear. This means you can't just plug in numbers and apply linear algebra.
The brute force method is to create variable arrays and try all combinations. The solver iterates until outputs are within a specified range. You can start at low resolution and wide limits and successively narrow. A commercial package will automate the process.
The goal is not necessarily to find exact values. When optimizing you are looking for a workable solution. Process controls are an example. A complex system can have hundreds of equations.
If you run it you can experiment with different equations. You can solve simultaneous differential equations. It can be a lot faster than trying to find a closed soltion toa problem.
a = 2*x + y[j];
b = x + pow(2.718,y[j]);
Excel has a solver-optimizer.
Code:
const int TRUE = 1;
int nx = 0, ny = 0, i = 0, j = 0, hit = 0;
double xmax = 10, xres = .01;
double ymax = 10, yres = .01;
double a = 0, b = 0, c = 0;
double atarget = 7, _atol = .5,ahi = 0,alo = 0;
double btarget = 4, _btol = .5,bhi = 0,blo = 0;
int main()
{
nx = ceil(xmax/xres); ny = ceil(ymax/yres);
double *x = new double[nx];
double *y = new double[ny];
ahi = atarget + _atol; alo = atarget - _atol;
bhi = btarget + _btol; blo = btarget - _btol;
for(i = 0;i<nx;i++)x[i] = i * xres;
for(i = 0;i<ny;i++)y[i] = i * yres;
for(i = 0; i < nx; i++){
for(j = 0; j < ny; j++){
a = 2*x[i] + y[j];
b = x[i] + y[j];
if(a<ahi && a>alo && b<bhi && b>blo){
hit = TRUE;
break;
}//if
}//j
if(hit)break;
}//i
if(hit){
printf("a %f b %f\n",a,b);
printf("x %f y %f\n",x[i],y[j]);
}//if
else printf("MISS\n");
return 0;
}
//main()
Last edited:
steve_bank
Diabetic retinopathy and poor eyesight. Typos ...
Fractional Numbers
There are floating point ad fixed point dugital resentaion of numbrrs. Floating point ranges from very small frcational numbers to large integers and the decimal pony movies based on the number.
In embedded applications if you know the limits of the numbers before hnd fractional numbers an run faster and take less space. Not as much of an isue with fast 32 bit microcontrollers, but with a simple application like a temperature sensor and control system an 8 bit fractional number may be sufficient.
Consider a 16 bit fractional number with a sign bit, 7 integer bits, and 8 fractional bits. The smallest number is fixed at 1/2^8, .00390625 th frictional east significant bit and the smallest number. The maxim integer is 2^7 127.
For the fractional part value = b0*lasb*2^0 + b1*lsb*2^1...+b7*lsb*2^7
in hex 16 bits, 1 sign bit ,7 integer bits, 8 fractional bits.
0x7f00 = 127
ox0080 = 0.5
0x 0140 = 1.25
0x01c0 =1 .75
Binary fractional multiplication is done as in decimal. Shift, multiply digit by digit and add. Integer multiplication then set the decimal point.
In binary multiplication like decimal on paper you need more digits than each variable for the resut. For a 16 x16 bit multiplication you need a 32 bit accumulator. Shift right to set the decimal point.
I didn't work out handling negative numbers.
There are floating point ad fixed point dugital resentaion of numbrrs. Floating point ranges from very small frcational numbers to large integers and the decimal pony movies based on the number.
In embedded applications if you know the limits of the numbers before hnd fractional numbers an run faster and take less space. Not as much of an isue with fast 32 bit microcontrollers, but with a simple application like a temperature sensor and control system an 8 bit fractional number may be sufficient.
Consider a 16 bit fractional number with a sign bit, 7 integer bits, and 8 fractional bits. The smallest number is fixed at 1/2^8, .00390625 th frictional east significant bit and the smallest number. The maxim integer is 2^7 127.
For the fractional part value = b0*lasb*2^0 + b1*lsb*2^1...+b7*lsb*2^7
in hex 16 bits, 1 sign bit ,7 integer bits, 8 fractional bits.
0x7f00 = 127
ox0080 = 0.5
0x 0140 = 1.25
0x01c0 =1 .75
Binary fractional multiplication is done as in decimal. Shift, multiply digit by digit and add. Integer multiplication then set the decimal point.
In binary multiplication like decimal on paper you need more digits than each variable for the resut. For a 16 x16 bit multiplication you need a 32 bit accumulator. Shift right to set the decimal point.
I didn't work out handling negative numbers.
Code:
float fixpt2dec(unsigned int num, int nint, int nfrac){
//converts fixed point to decimal for dsplay
// sign bit 1 is negative
int i;
unsigned int mask = 1;
float fraclsb, decval = 0;
fraclsb = 1 / pow(2, nfrac);
//fractional sum
for (i = 0; i < nfrac ; i++) {
if (mask & num) decval += (fraclsb * pow(2, i));
mask = mask << 1;
}
//integer sum
for (i = 0; i<nint;i++){
if (mask & num) decval += pow(2, i);
mask = mask << 1;
}
if(num&mask)decval = decval * -1.;
return(decval);
}//fixp2dec()
int main()
{
double decval = 0;
int Nbits = 16, Nfrac = 8, Nint = 7;
unsigned int a = 0x7f00, b = 0x0100;
unsigned int acc = 0,mask = 1;
double dv1 = 0,dv2 = 0;
int nbits = 15,i;
// multiply shift and add
for (i = 0; i < nbits; i++)if (a & (mask << i)) acc += (b << i);
acc = acc >>8; // set decimal point
// decimal values for display
dv1 = fixpt2dec(a, Nint, Nfrac);
dv2 = fixpt2dec(b, Nint, Nfrac);
printf("a %3.10f b %3.10f\n",dv1,dv2);
// decimal value of multiplication product
decval = fixpt2dec(acc, Nint, Nfrac);
printf("acc 0X%x\n",acc);
printf("decval %4.8f\n",decval); ;
return(0);
}steve_bank
Diabetic retinopathy and poor eyesight. Typos ...
Adding that a harware barrel shifter is used in hardware multipliers along with an accumulator to the shift and add fast without clocked sequential logic.
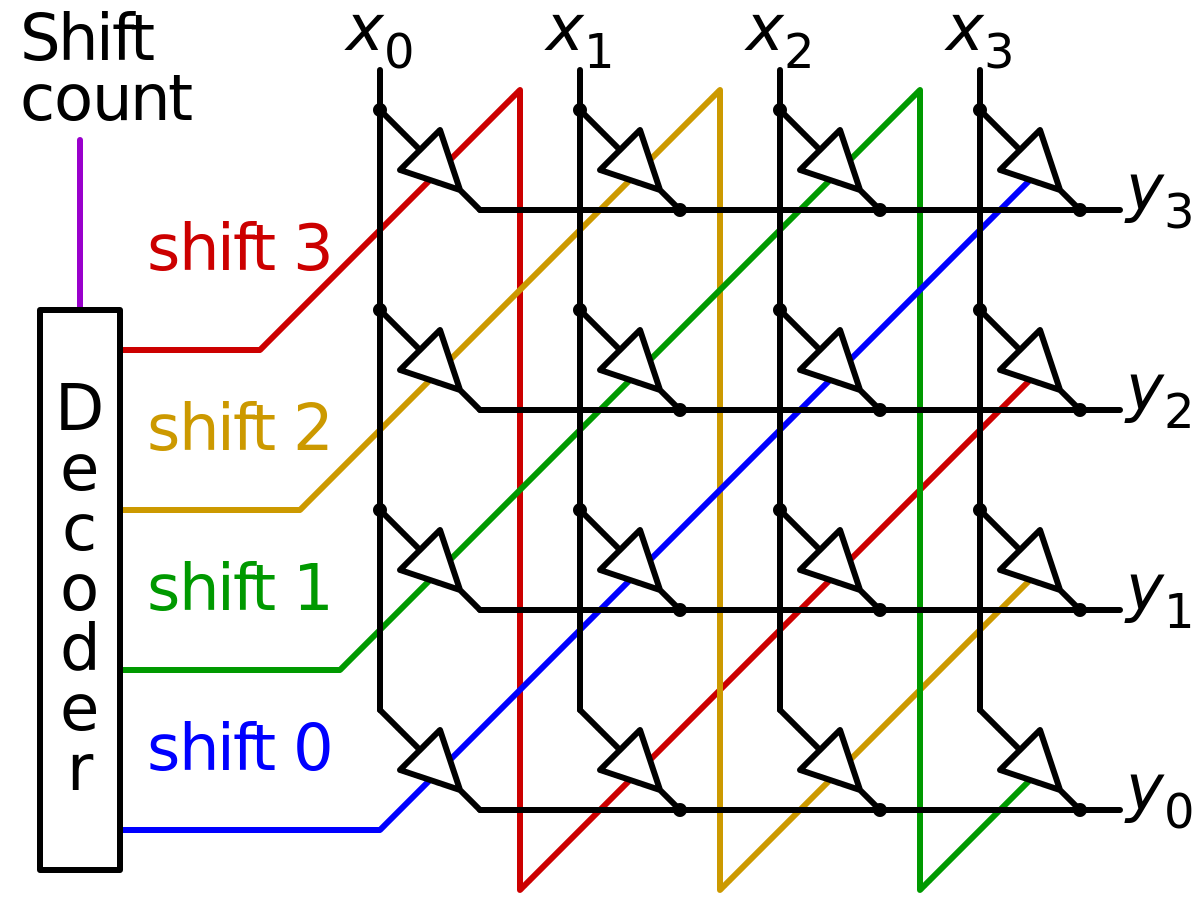
 en.wikipedia.org
en.wikipedia.org
Barrel shifter - Wikipedia
A barrel shifter is a digital circuit that can shift a data word by a specified number of bits without the use of any sequential logic, only pure combinational logic, i.e. it inherently provides a binary operation. It can however in theory also be used to implement unary operations, such as logical shift left, in cases where limited by a fixed amount (e.g. for address generation unit). One way to implement a barrel shifter is as a sequence of multiplexers where the output of one multiplexer is connected to the input of the next multiplexer in a way that depends on the shift distance. A barrel shifter is often used to shift and rotate n-bits in modern microprocessors,[citation needed] typically within a single clock cycle.
For example, take a four-bit barrel shifter, with inputs A, B, C and D. The shifter can cycle the order of the bits ABCD as DABC, CDAB, or BCDA; in this case, no bits are lost. That is, it can shift all of the outputs up to three positions to the right (and thus make any cyclic combination of A, B, C and D). The barrel shifter has a variety of applications, including being a useful component in microprocessors (alongside the ALU).
A common usage of a barrel shifter is in the hardware implementation of floating-point arithmetic. For a floating-point add or subtract operation, the significands of the two numbers must be aligned, which requires shifting the smaller number to the right, increasing its exponent, until it matches the exponent of the larger number. This is done by subtracting the exponents and using the barrel shifter to shift the smaller number to the right by the difference, in one cycle.
lpetrich
Contributor
Does anyone here have any experience with GUI programming?
This includes the halfway GUI's of text-mode terminals like the VT100 and their emulators in many full-GUI systems.
I only did a tiny bit: using its escape codes to produce twice-size text - one for the upper half and one for the lower half.
But for full GUI's, it's a long list:
This includes the halfway GUI's of text-mode terminals like the VT100 and their emulators in many full-GUI systems.
I only did a tiny bit: using its escape codes to produce twice-size text - one for the upper half and one for the lower half.
But for full GUI's, it's a long list:
- MacOS Classic
- MacOS Cocoa - updated NeXTStep
- Windows - using Borland's app framework long ago
- Java AWT
- Python/TK - tkinter
- Android
- HTML / CSS / JavaScript
Jarhyn
Wizard
- Joined
- Mar 29, 2010
- Messages
- 17,426
- Gender
- Androgyne; they/them
- Basic Beliefs
- Natural Philosophy, Game Theoretic Ethicist
Yeah, I've experience in using markup models to drive GUIs out: XAML and the likeDoes anyone here have any experience with GUI programming?
This includes the halfway GUI's of text-mode terminals like the VT100 and their emulators in many full-GUI systems.
I only did a tiny bit: using its escape codes to produce twice-size text - one for the upper half and one for the lower half.
But for full GUI's, it's a long list:
- MacOS Classic
- MacOS Cocoa - updated NeXTStep
- Windows - using Borland's app framework long ago
- Java AWT
- Python/TK - tkinter
- Android
- HTML / CSS / JavaScript
I could probably shake off the rust (let's be fair, it was rusty even when I first learned it) on my 3d graphics knowledge kicking around in there too, although my brain will hate me for putting it back through Euler rotations again.
Why do you ask?
lpetrich
Contributor
I was curious if anyone else had any experience with GUI programming that they might want to share.
Like GUI builders vs. programmatic GUI's.
Like GUI builders vs. programmatic GUI's.
Last edited: